Introduction
In truly adversarial spaces, deep learning models find themselves at risk of attack from adversarial models. In many real world cases, this can prove to be detrimental in the performance of these deep learning models and can have significant real world impact when they are exploited. As a result, we want to look into the idea of whether or not classifiers can be developed to be robust to these adversarial examples. Adversarial attacks are methods used to interfere with deep learning systems- with the intent of finding ways to misclassify data. These attacks generally come in the form of targeted and untargeted attacks. Targeted attacks entail manipulating data to output a desired outcome after feeding it to a model, while untargeted attacks focus on manipulating data to simply not be recognized as it’s correct output. We will analyze ways in which models can be trained to overlook adversarial examples through robustness. Robustness refers to the ability of an algorithm to perform strongly even when there are shifts or changes in what it is seeing, even if the base class is the same. An example of this would be photoshopping an image of a medical condition and training the model to still determine what that medical condition is, even with the unfamiliar, edited element on the image. Increasing the robustness of a model can be used to prevent possible edge cases from decreasing the accuracy of a model. We will be analyzing the methods described in Adversarial Attacks Against Medical Deep Learning Systems on adversarial attacks and adversarial training, as well as exploring robust training methods we would like to apply to medical deep learning systems. For the purpose of this paper, we will look into the dermatology case specifically to better understand the usage of adversarial attacks against deep learning systems used in determining whether or not a skin condition shows signs of melanoma, a form of skin cancer.
Background
An area where deep learning systems find themselves particularly at risk for adversarial attacks is within the healthcare space. Healthcare is fundamentally a sensitive space, with patient data being highly protected and every decision made having a lasting impact on the health of the people that are involved. As technology advances within this sector, deep learning algorithms are being used for new tasks, including diagnosing patients with conditions based on viewing medical images such as photographs, x-rays, and other diagnostic scans. In cases where adversarial examples attack these deep learning models, the possibilities for misdiagnosis and subsequent fraud and bodily harm begin to grow. We want to determine how to develop robust solutions to protect this sensitive data and model predictions against such adversarial examples.
In the case of these adversarial attacks here, we wanted to get a further understanding of what parts of the algorithm these attacks tend to focus on. The understanding is that these deep learning algorithms are built using neural networks, particularly convolutional neural networks as is usually the case when working with image inputs (University of Michigan). Convolutional neural networks, or CNNs for short, work through the usage of layers that handle functionalities such as decreasing the computational power required to process the data through dimensionality reduction, extracting dominant features, and flattening in order to produce the proper classification output (Saha). In the case of this replication, we have used the same pre-trained ImageNet models with tuned parameters for classification and pre-trained ResNet-50 models to build our networks as the source material.
When it comes to the adversarial attacks, they can affect all sections of the model pipeline. Training data can be affected by data breaches and bias,training can be affected by improper training, the model can be affected by privacy breaches, deployment by system disruption and shifts on real-world data, and results by model stealing. In the scope of this paper, we will implement human-imperceptible attacks through projected gradient descent and patch attacks, both of which will be covered in the Methods section of this report.
Theory: Adversarial Attacks
We now explore adversarial attacks and their different types. Examples of adversarial attack strategies include utilizing the Fast Gradient Descent Method and Projected Gradient Descent to Lower bound the inner maximization problem.
We will now discuss the inner maximization problem.
We notice that h(theta) represents our model, while x is the data we feed into the model, and Y is the final output. The idea for this is that rather than minimizing the loss of our data to find the label which has the least loss when compared to our data, we want to maximize this loss to find the label that has the largest loss value from our label. These attacks are considered ‘untargeted’ as they aim to simply ensure the data fed is misclassified. For a targeted attack, we use the same strategies as specified for untargeted attacks, except in this case we misclassify our data to a specific classification.
The difference between the two attacks is that a targeted attack must not only maximize the loss of the real data label, but also minimize the loss for our target label.
Adversarial Training
The process of adversarial training largely revolves around the idea that creating and utilizing adversarial examples within the training process of a model will allow that model to better protect against such adversarial examples being used against it in real world practice. The main questions asked when it comes to adversarial training revolve around which adversarial examples to use within the training process. When looking into this, it can be seen that the main aspects to consider in adversarial training is that the strong attacks should be incorporated into the inner maximization problem of the algorithm in this case. General consensus in the data science community indicates that the best way to do this is through projected gradient descent methods. When it comes to how this training is structured, the following formulas can better visualize how this process works.
Beyond this, it is common to randomize over the starting positions in projected gradient descent in order to avoid issues when it comes to the procedure learning loss surface. During our replication of the code for this report, we decided to utilize the pre-trained models given to us in order to offer more consistent results and performance in the later parts of our research, which we have cited in our Github repository.
Robust Training
Robust training also finds use in convex relaxation methods, also known as providing the provable upper bounds on objectives. If we are able to add upper bounds to check the robustness of the model against adversarial examples, we can use the upper bound to help us make a model that minimizes losses based on that bound.
Robust training is focused around the idea of minimizing loss based on an upper bound. In this case, training in this case will allow for the discovery of meaningful bounds. In order to do this, we must “the interval bounds to upper bound the cross entropy loss of a classifier, and then minimize this upper bound” (Adversarial Robustness - Theory and Practice). We believe that in future exploration of adversarial attacks in healthcare deep learning systems, a deeper look into robust training can provide more insight into how we may better combat adversarial examples in real world settings.
Methods
Fast Gradient Sign Method
The Fast Gradient Sign Method is one of the methods that we will experiment with using for adversarial robust training. Fast gradient sign method is an adversarial method that utilizes the gradients of a neural network’s loss in order to affect the input image in order to maximize the loss value. Training around this would allow the neural network to account for a seemingly worst case scenario where losses are maximized, allowing the model to better protect against adversarial attacks that are imperceptible to humans. The Fast Gradient Sign Method for adversarial attacks is represented by the equation:
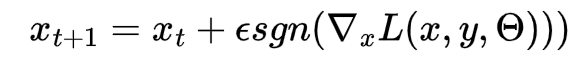 FGSM equation, Tensorflow Documentation
FGSM equation, Tensorflow Documentation
Projected Gradient Descent
We explore Projected Gradient Descent as a standard for traditional adversarial training in order to compare the effectiveness of the Fast Gradient Sign Method results. Projected Gradient Descent (PGD) is known to be effective in training for adversarial attacks, however can be computationally expensive to run. Its goal is to solve the inner maximization problem over a threat model, where threat model refers to the type of attack to be performed on a model (ie white box attack, black box attack, targeted vs untargeted attack).
 PGD pseudocode (Wang et al)
PGD pseudocode (Wang et al)
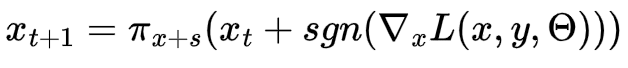 PGD equation, Tensorflow Documentation
PGD equation, Tensorflow Documentation
Results
Diabetic Retinopathy
For the purpose of recording our results for diabetic retinopathy, we ran the same FGSM training model with changing epsilon values. In this case, epsilon represents the coefficient of the loss functions as seen in the FGSM equation. Diabetic retinopathy represented our largest dataset, coming in with 10644 images. As a result, our code had to be optimized to run effectively within the computing resources available to us while also taking into account this large dataset. As a result, this section was run on algorithms with epsilons 0, 5, and 8 with attack epsilons of 0, 2, 5, and 8. Epsilon 0 on the training algorithm indicates that the algorithm does not have robust training while higher epsilons indicate higher levels of robust training. When looking at the attack epsilon, an epsilon of 0 indicates no adversarial attack while higher epsilons indicate stronger attacks. Using FGSM, we were able to gauge the following results from those runs:
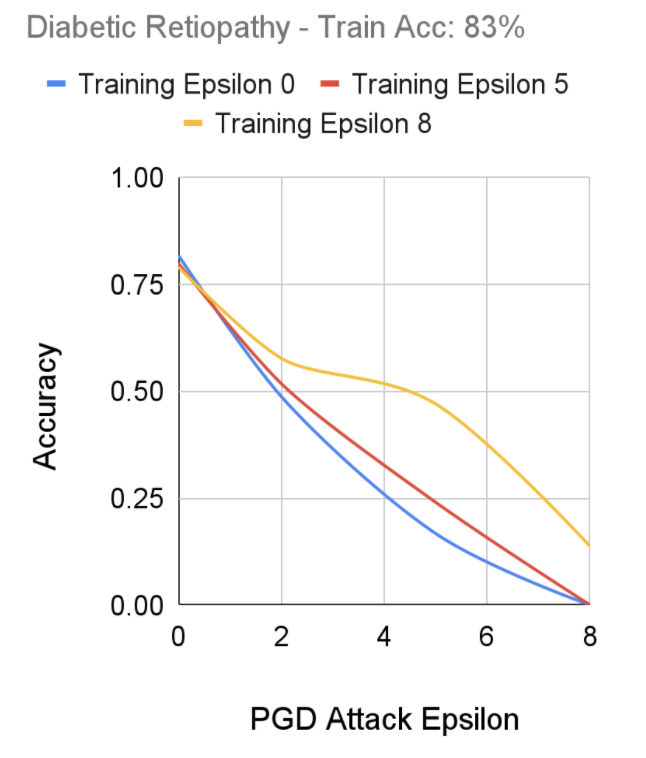 FGSM Robust Training Performance on Diabetic Retinopathy Dataset, Senthilvelan & Tjoa
FGSM Robust Training Performance on Diabetic Retinopathy Dataset, Senthilvelan & Tjoa
Dermatology Skin Patches
After performing training using Fast-FGSM on our dataset, we notice our models that had Epsilon 5 and 8 training epsilons performed relatively consistently against adversarial attacks between 0 to 9 epochs. Alternatively, we notice the training set with epsilon 0 outputted a lower accuracy as the epsilon of the adversarial attacks increased; with our takeaway being of a similar structure to our Diabetic Retinopathy results regarding the effectiveness of robustly trained models on epsilon attacks.
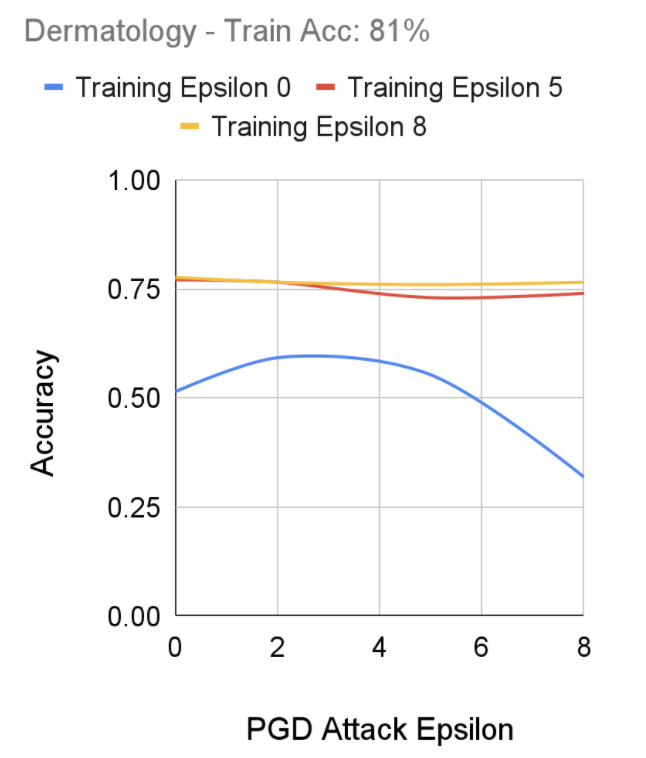 FGSM Robust Training Performance on Dermatology Dataset, Senthilvelan & Tjoa
FGSM Robust Training Performance on Dermatology Dataset, Senthilvelan & Tjoa
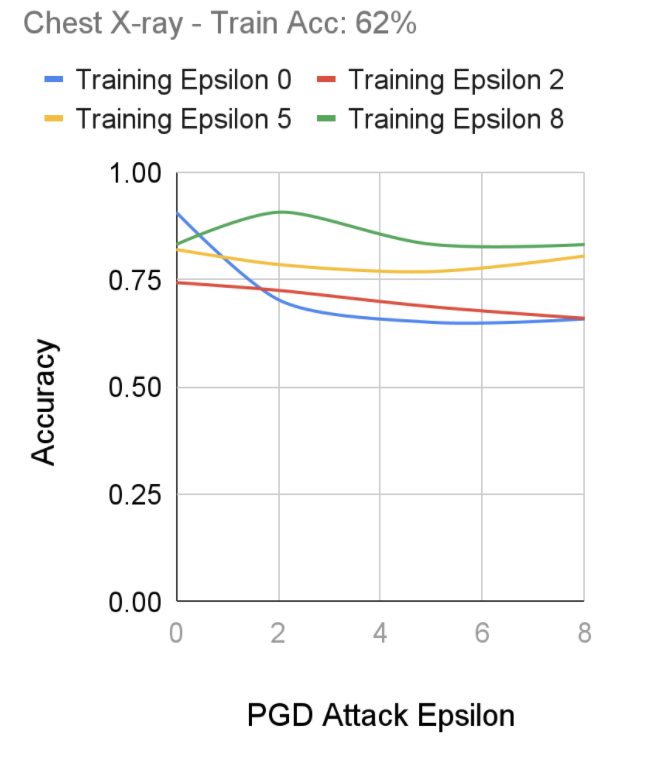
Chest X-rays
After performing training using Fast-FGSM on our chest x-ray dataset, we notice a more prominent effect of robust training as the standard model (Training Epsilon 0) shows a high accuracy on regular images, which promptly decreases as the adversarial attacks intensify. On the other hand, we notice our most robustly trained model (Training Epsilon 8), seems to perform consistently against the various adversarial attacks, although its initial training accuracy on non-adversarial images did not perform as well as the standard model. Interestingly, we don’t seem to notice a major tradeoff between the robustness of a model and the accuracy compared to less robust models.
 FGSM Robust Training Performance on Dermatology Dataset, Senthilvelan & Tjoa
FGSM Robust Training Performance on Dermatology Dataset, Senthilvelan & Tjoa
Conclusion
From our research, we can see that robust training allows for better performance in deep learning systems in the Fast-FGSM. We can see that the robust training allows the model to be better prepared for adversarial attacks and that a more robust algorithm could help handle the cases where ours was unable to detect the adversarial attacks. In our case, we were unable to explore stronger models due to the computing constraints we faced. However, based on our findings, we believe that experimenting with different parameters such as higher training epsilon, training with more epochs, further optimizing the Fast-FGSM algorithm, using a deeper neural network, or having access to more training data among other factors may help in further advancing the performance and efficiency of robust training against adversarial attacks in healthcare. Considering the significant ramifications of adversarial attacks being deployed onto sensitive healthcare systems, the value of robust training in these systems is very apparent.